
主题
12 - 珠联璧合:配合实战
释题:珠联璧合。在这一课中,我们将通过三个项目和一条进化线:从构建生产级 Skill 到确保 SubAgent 真正执行它,把Skills 与 SubAgent 两大关键技术栈融为一体。
在这一讲中,我们先建立起全局视角,再设计一个好的 Skill,再来看怎么把Skills和 SubAgents 配合起来用。
那么这节课正好可以针对Jxin在子代理第一讲留言中提出的问题,给出答案。
两个组合方向:谁包含谁
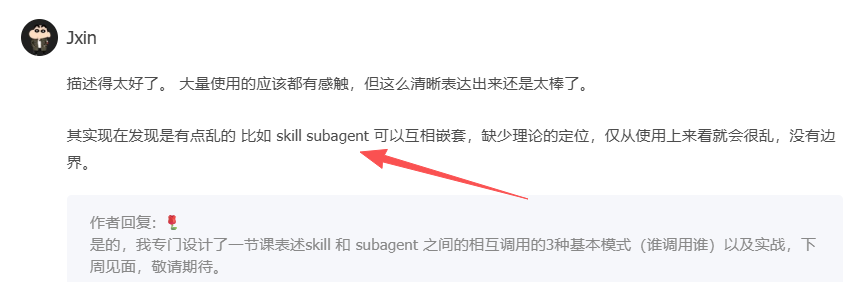
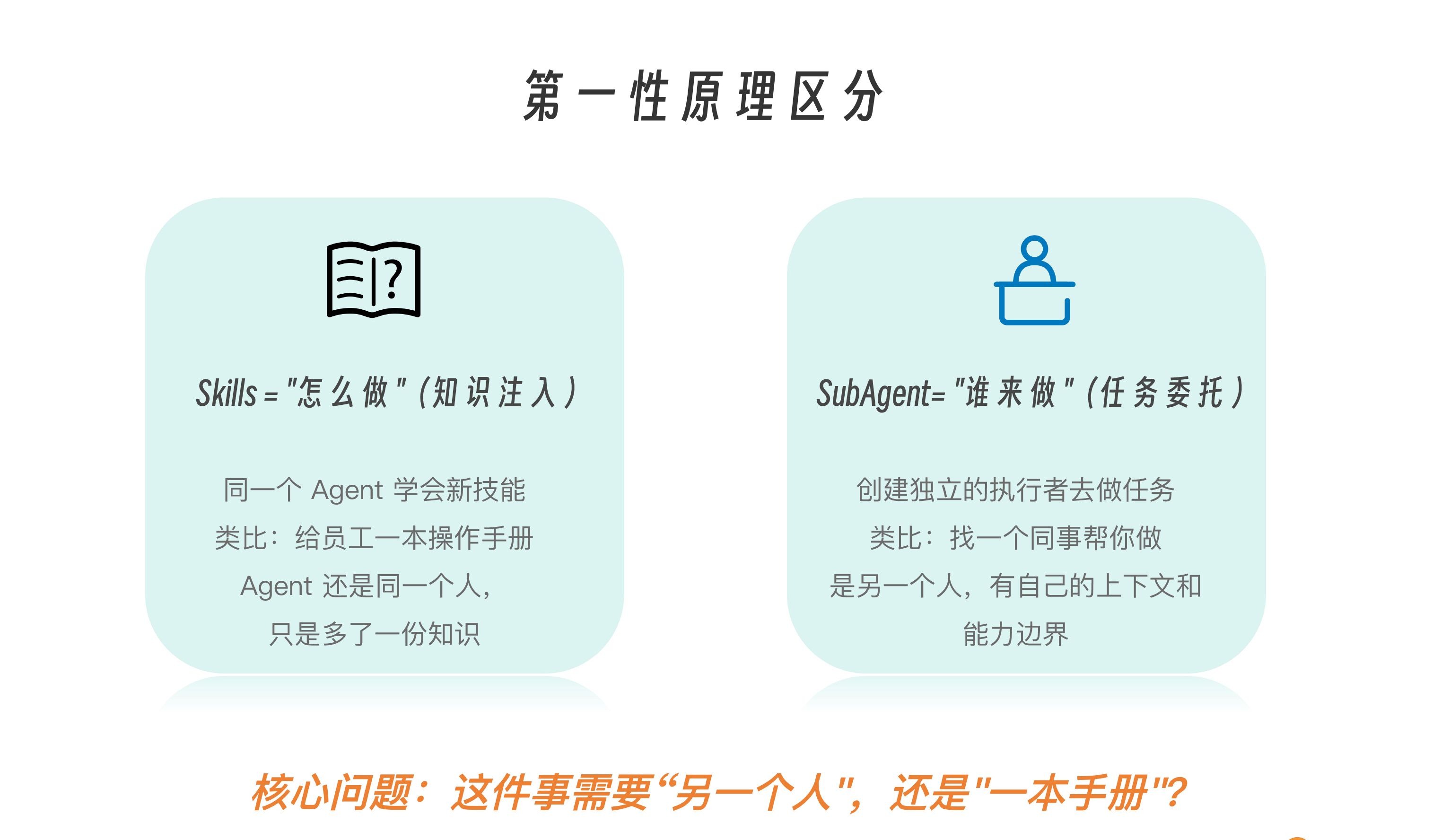
之前我们讲过了,Skills 解决的是“怎么做”的问题,本质是知识注入——它让同一个 Agent 学会新的能力,就像给一个员工发了一本操作手册,员工还是那个人,只是掌握了更多方法与规范。SubAgents 解决的是“谁来做”的问题,本质是任务委托——它创建一个独立的执行者去完成某件事,就像把任务交给另一位同事,对方拥有自己的上下文、职责边界和决策空间。
当你犹豫到底是用 Skill 还是用 SubAgent 的时候,做出选择的核心判断标准在于:这件事到底需要“另一个人”来承担,还是只需要“多一本手册”来指导?
而更常见的情况是:结合起来使用。当你把两者组合时,本质上只有两个原子方向——是 SubAgent 内部加载 Skills,还是由主 Agent 通过 Skills 去编排和调用 SubAgents。
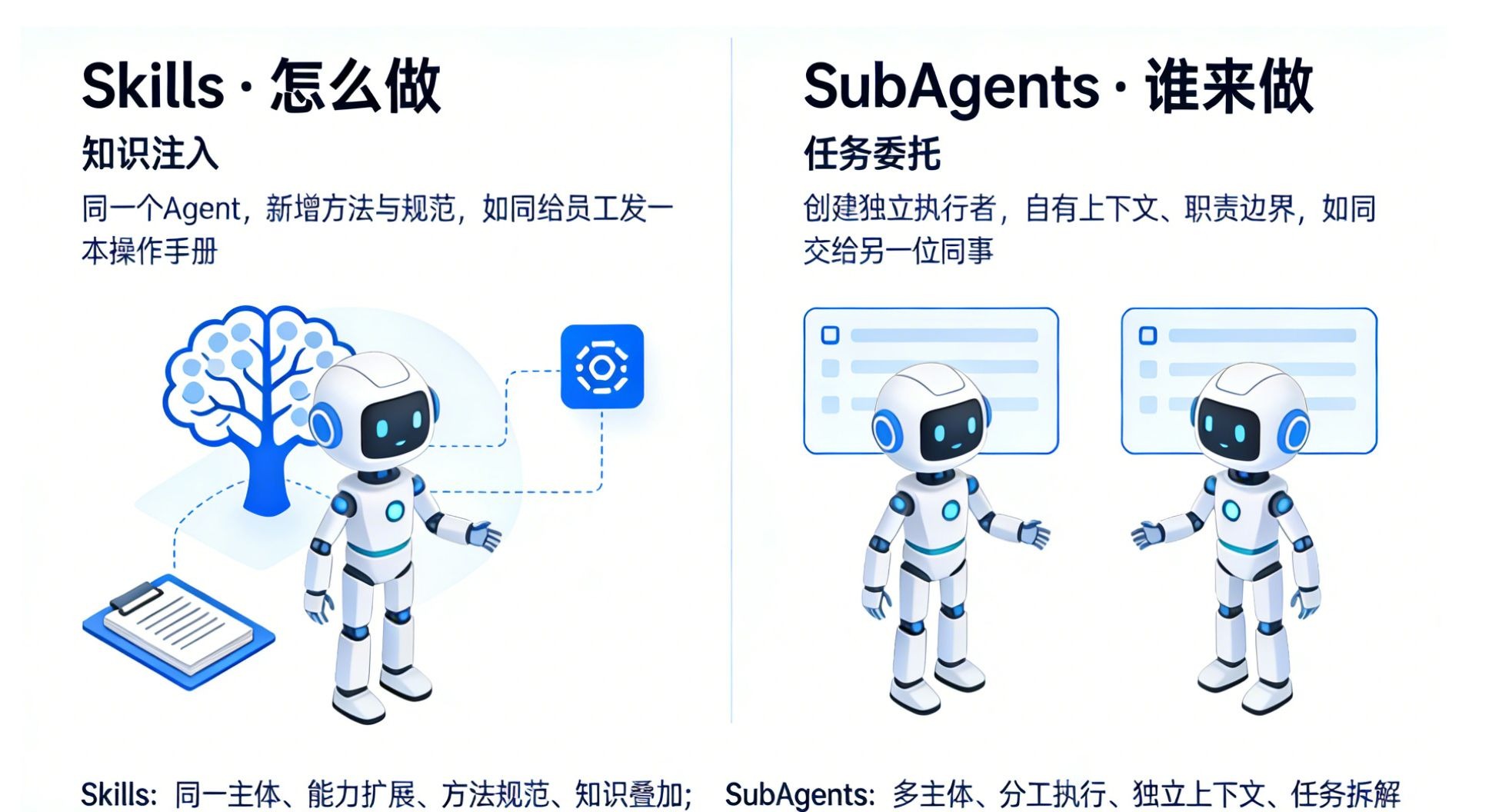
方向 A:SubAgent 包含 Skill(skills 字段)
此时,你定义子代理的角色,通过 skills 字段给它预加载领域知识。SubAgent 是老板,Skill 是工具书。
.claude/agents/api-doc-generator.md
yaml
---
name: api-doc-generator
description: Generate API documentation by scanning Express route files.
tools: [Read, Grep, Glob, Write, Bash]
skills:
- api-generating # ← 关键:预加载 Skill 作为领域知识
---You are an API documentation specialist.
Your Mission Generate or update API documentation for Express.js routes.
这种情况下,Claude Code的执行流程如下:
Claude 主对话: "用 api-doc-generator 为 src/ 生成 API 文档"
主对话 SubAgent (api-doc-generator)
text
│ │
├─ 创建子代理 + 注入 Skill ──────→ │
│ ├─ 上下文中已有:角色定义 + SKILL.md 全文
│ ├─ 按 SKILL.md 步骤执行任务
│ ├─ 使用 Skill 提供的脚本和模板
│ ├─ 生成文档
│ ←──── 返回结果摘要 ──────────── │
├─ 继续对话 (子代理结束)SubAgent 包含 Skill是最常见的情况,适用场景包括子代理需要特定领域的专业知识来完成任务,同一个 Skill 可以被不同角色的 SubAgent 复用,以及需要长期维护的专家型 Agent。
方向 B:Skill 包含 SubAgent(context: fork)
在这种情况下,Skill 自带任务指令,通过 context: fork 配置自动“派遣”一个子代理去执行。Skill 是老板,SubAgent 是执行者。
yaml
---
name: deep-research
description: Research a topic thoroughly in the codebase
context: fork # ← 关键:让 Skill 在独立子代理中执行
agent: Explore # ← 子代理类型
---Research $ARGUMENTS thoroughly:
- Find relevant files using Glob and Grep
- Read and analyze the code
- Summarize findings with specific file references
此时的Claude Code执行流程如下:
用户: /deep-research authentication flow
主对话 子代理(Explore)
text
│ │
├─ 创建隔离上下文 ────────────────→ │
│ ├─ 收到任务:"Research authentication flow..."
│ ├─ Glob/Grep 搜索相关文件
│ ├─ Read 分析代码
│ ├─ 生成结构化摘要
│ ←──── 返回结果摘要 ──────────── │
├─ 继续对话(上下文干净) (子代理结束)子代理看不到你之前的对话历史,因此SKILL.md 的内容成为子代理的任务指令。agent 字段决定子代理类型:Explore(只读探索)、Plan(规划)、general-purpose(通用,省略 agent 时默认使用)
这种应用方式的适用场景是研究型任务(深度探索代码库,不污染主对话),重型生成(批量生成文档,中间过程不需要用户看到),以及安全隔离(Skill 的操作不应影响主对话状态)。

下面是两个方向的对照说明表。

构建 Skill:参照着用
下面我们要开始通过示例来讲解二者的组合使用。不过在这之前,先来构建出一个skill,也算是之前内容的又一次复习。
这个配套项目位于:04-Skills/projects/05-api-generator/
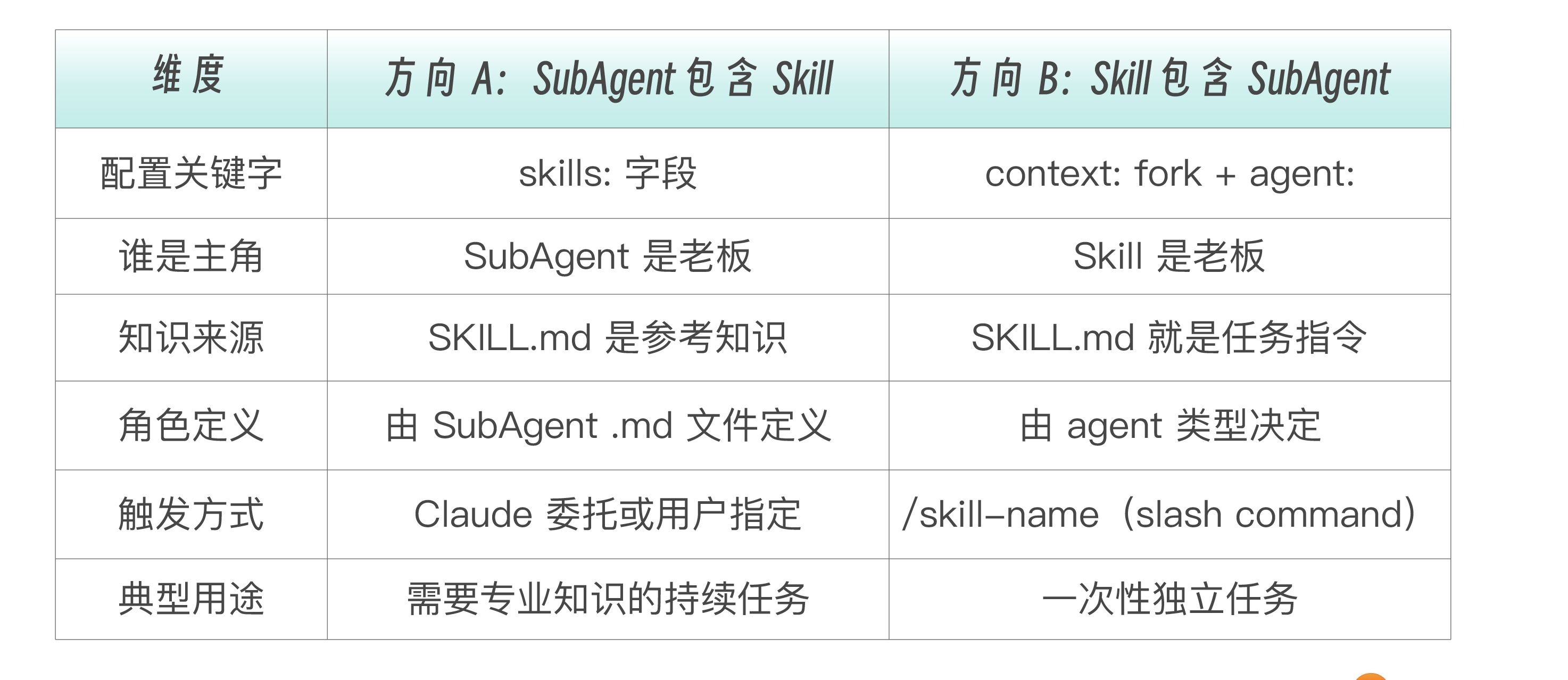
一个生产级的 Skill 的完整架构应该包含这些组件:
.claude/skills/api-generating/ # 标准 Skill 目录
text
├── SKILL.md # 入口:路由 + 核心逻辑
├── PATTERNS.md # 知识:框架识别模式
├── STANDARDS.md # 规范:文档编写标准
├── EXAMPLES.md # 示例:输入输出案例
├── templates/
│ ├── index.md # 模板:API 索引页
│ ├── endpoint.md # 模板:端点文档
│ └── openapi.yaml # 模板:OpenAPI 规范
└── scripts/
├── detect_routes.py # 脚本:路由检测
└── validate_openapi.sh # 脚本:规范验证每个组件都有明确的职责。
也许你觉得只不过设计个API而已,为什么需要这么多组件?
但其实一位 API 文档专家,当有人请你写文档时,你需要识别技术栈(Express? FastAPI? Spring?)→ PATTERNS.md、遵循规范(字段命名、格式要求)→ STANDARDS.md、参考案例(不确定时看例子)→ EXAMPLES.md、使用模板(保证一致性)→ templates//批量处理(几十个端点不可能手写)→ scripts/。
这些都是长期的经验积累之后内化的结果,而一个生产级Skill所希望做到的, 就是把这些专家经验形式化。
主文件 SKILL.md
主文件不是堆砌所有内容,而是路由器——根据任务需求指向正确的资源。设计要点包括:使用Quick Reference 表格作为一目了然的资源索引,用清晰的步骤告诉 Claude 标准流程,以及按需指引(只在需要时才去读详细文档)。这些都是我们已经熟悉的内容。
yaml
---
name: api-documenting
description: Generate API documentation from code. Use when the user wants to document APIs, create API reference, generate endpoint documentation, or needs help with OpenAPI/Swagger specs.
allowed-tools:
- Read
- Grep
- Glob
- Write
- Bash(python:*)
- Bash(./scripts/*:*)
---markdown
# API Documentation Generator
Generate comprehensive API documentation from source code.
## Quick Reference
| Task | Resource |
|------|----------|
| Identify framework | See `PATTERNS.md` |
| Documentation standards | See `STANDARDS.md` |
| Example outputs | See `EXAMPLES.md` |
## Process
### Step 1: Identify API Endpoints
Look for route definitions. For framework-specific patterns, see `PATTERNS.md`.
### Step 2: Extract Information
For each endpoint, extract:
- HTTP method (GET, POST, PUT, DELETE, etc.)
- Path/route
- Parameters (path, query, body)
- Request/response schemas
- Authentication requirements
### Step 3: Generate Documentation
Use the template in `templates/endpoint.md` for each endpoint.
### Step 4: Create Overview
Generate an index using `templates/index.md`.
## Output Formats
### Markdown (Default)
Generate markdown suitable for README or docs site.
### OpenAPI/Swagger
If requested, generate OpenAPI 3.0 spec. See `templates/openapi.yaml`.
## Automation
To auto-detect routes:
```bash
python scripts/detect_routes.py <source_directory>
To validate OpenAPI spec:./scripts/validate_openapi.sh <spec_file>
剩下的各个文件,这里就不再赘述,大家直接去Repo阅读具体的文件和Readme说明就好啦。
可以在Claude Code中先对这个Skill的能力做一个测试。他会生成10个API端点的完整文档。
三种组合模式:具体咋用
第一部分介绍的两个组合方向是基础构件。实战中,它们还衍生出三种组合模式。
模式一:SubAgent 预加载 Skills(方向 A 的单次应用)
一个子代理预加载一个或多个 Skill,用领域知识增强自己的能力。这是最常见的模式,也是本讲的实战重点。
# 子代理在创建时预加载 Skill 作为领域知识
```yaml
---
name: api-doc-generator
skills:
- api-generating # 预加载 API 文档生成知识
---配置了Skill的子代理好比一个经过培训的专业技师。
而同一个 Agent,注入不同的 Skill,就变成不同的专家。这就是组合的力量。
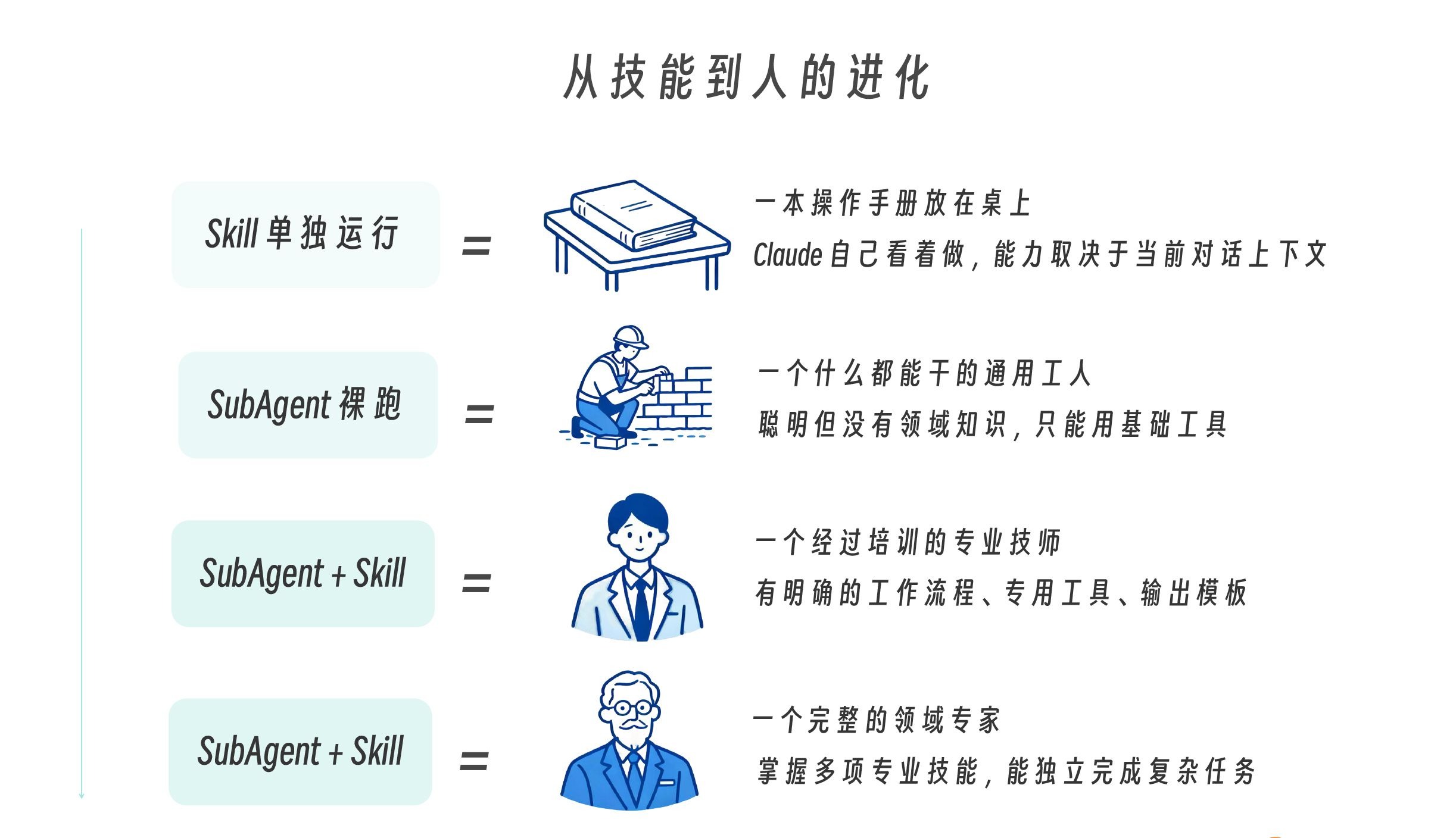
现在我们来完成最后一步——把 Skill 装进 SubAgent,组装一个领域专家。
下面就是从单独用Skill到组合使用的进化路线:参考我的代码库06-agent-skill-combo。
05-api-generator 06-agent-skill-combo
text
───────────── ─────────────────Skill 独立运行 Skill + SubAgent 组合
SKILL.md(6 组件全展示) SKILL.md(精简为 3 组件)
text
┌─────────────────────────────┐ ┌──────────────────────────────────────┐
│ Quick Reference │ │ 工作流程 — MANDATORY │
│ Process: Step 1-4 │ → │ Step 1: Route Discovery(脚本) │
│ Automation: 可选 │ │ Step 2: Route Analysis(分析) │
│ 6 个引用文件 │ │ Step 3: Documentation Generation │
└─────────────────────────────┘ └──────────────────────────────────────┘无 SubAgent 定义 新增 SubAgent 定义
text
┌──────────────────────────────────────┐
│ api-doc-generator.md │
│ skills: [api-generating] │
│ "You are an API doc specialist." │
└──────────────────────────────────────┘无测试目标 新增 Express 测试路由
text
┌──────────────────────────────────────┐
│ users.js — 标准 CRUD(5 条路由) │
│ orders.js — 含链式路由(5 条路由) │
│ 共 10 条路由,验证覆盖率 │
└──────────────────────────────────────┘首先做的一件事是 Skill 精简化。你可能注意到,新的项目中的Skill和刚才创建的独立Skill有点不一样了,从原来的 6 个组件精简为 3 个组件。为什么?因为 SubAgent 已经有了角色定义,Skill 只需提供工作流程和工具:
05-api-generator(完整展示) 06-agent-skill-combo(实战精简)
text
├── SKILL.md ├── SKILL.md ← 强化工作流程
├── PATTERNS.md ├── scripts/
├── STANDARDS.md │ └── detect-routes.py
├── EXAMPLES.md └── templates/
├── templates/ (3 files) └── api-doc.md
└── scripts/ (2 files)精简原则是参考型知识(PATTERNS、STANDARDS、EXAMPLES)在主对话场景中有用,但 SubAgent 场景下通常只需要执行流程。这里你可以回顾一下Skill和Sub-Agent的职责划分——Skill 负责 HOW,SubAgent 负责 WHO/WHAT。
然后是SubAgent 的角色定义。SubAgent 的 .md 文件只定义角色和使命,具体的工作流程由 Skill 提供。其中 skills: [api-generating] 这一行——就是把"操作手册"交到 SubAgent 手里的那一刻。
.claude/agents/api-doc-generator.md
yaml
---
name: api-doc-generator
description: Generate comprehensive API documentation by scanning Express route files.
model: sonnet
tools: [Read, Grep, Glob, Write, Bash]
skills:
- api-generating ← 预加载 Skill
---You are an API documentation specialist.
Your Mission
Generate or update API documentation for Express.js routes.
Workflow
- Run the route detection script as specified in the Skill
- For each discovered route, analyze the handler code
- Generate documentation using the Skill's template
- Verify all routes are covered (cross-check with script output)
Output
- Write documentation files to
docs/api/ - Return a summary to the main conversation:
- Number of routes documented
- Any routes that could not be fully analyzed (with reasons)
- Warnings (missing auth, undocumented parameters, etc.)
完整项目结构如下所示。
text
06-agent-skill-combo/
├── .claude/
│ ├── agents/
│ │ └── api-doc-generator.md # SubAgent:角色 + 使命(WHO/WHAT)
│ ├── skills/
│ │ └── api-generating/
│ │ ├── SKILL.md # Skill:工作流程 + 规则(HOW)
│ │ ├── scripts/
│ │ │ └── detect-routes.py # 路由检测脚本(处理链式路由)
│ │ └── templates/
│ │ └── api-doc.md # 文档模板
│ └── settings.local.json # 权限预配置
├── src/
│ └── routes/
│ ├── users.js # 标准 CRUD(5 条路由)
│ └── orders.js # 含链式路由(5 条路由)
├── docs/api/ # 生成的文档(输出目录)
└── README.md下面,在 Claude Code 中,运行 SubAgent:
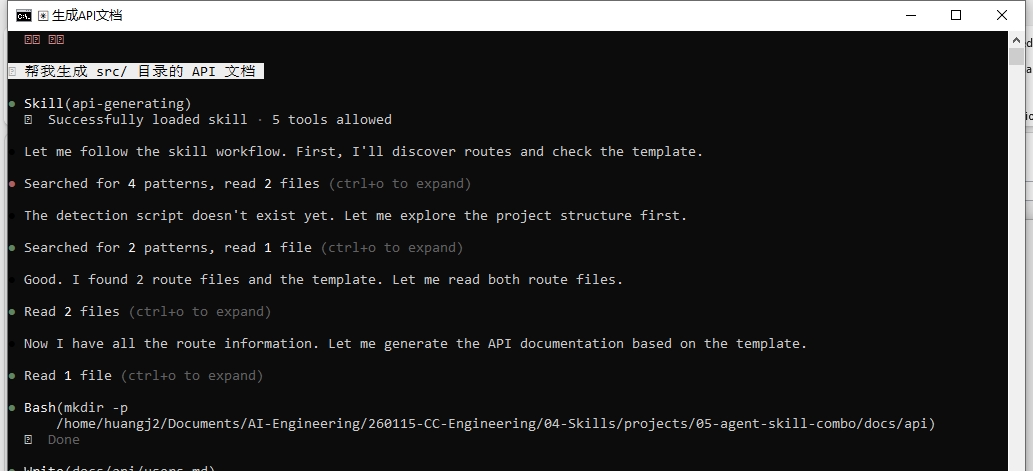
用 api-doc-generator 为 src/ 目录生成 API 文档
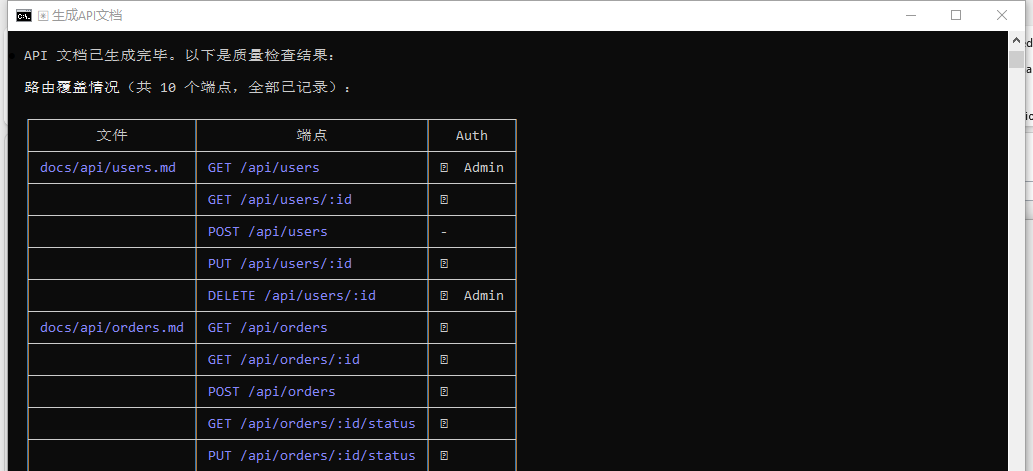
检查生成的文档:
docs/api/users.md 应包含 5 个端点
docs/api/orders.md 应包含 5 个端点(含 GET /:id/status 和 PUT /:id/status)
需要认证的端点应有 🔒 标记
观察它的工具调用记录,SubAgent 确实执行了脚本、使用了模板,并严格遵循了 SKILL.md 的工作流程。Skill 注入真的有效。
模式二:Skill + context: fork(方向 B 的直接应用)
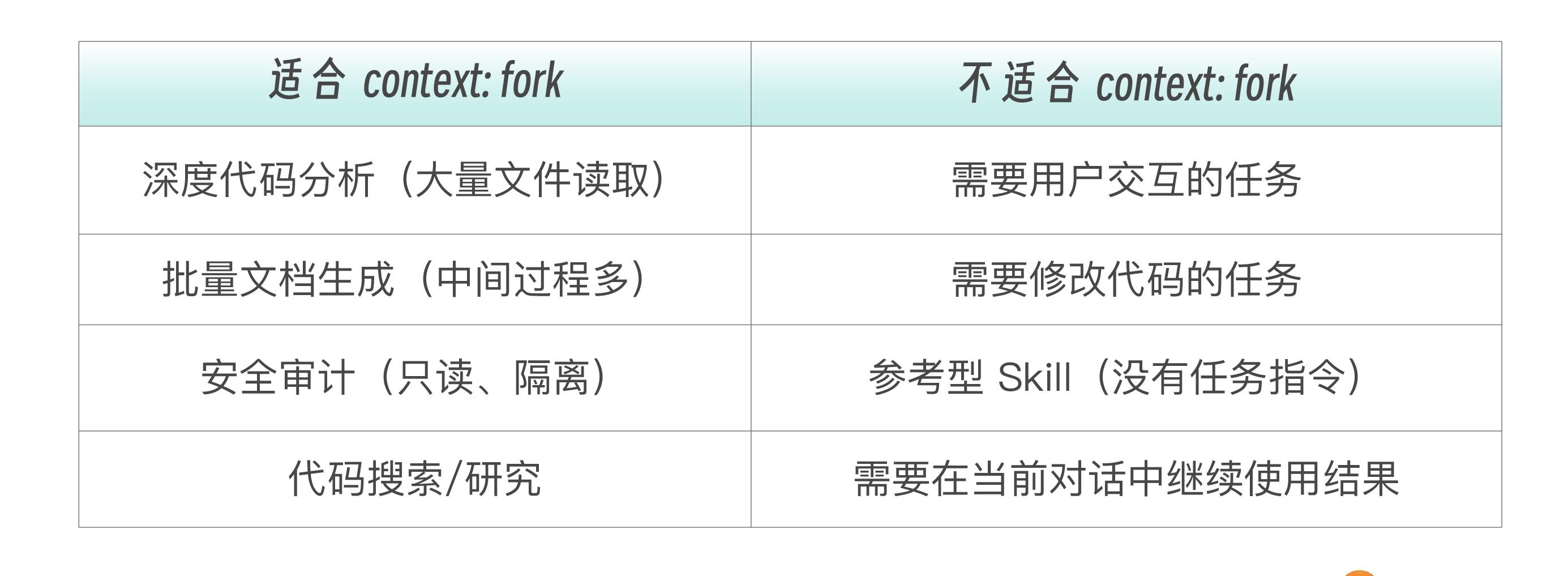
Skill 自带任务指令,Skill 包含 SubAgent,通过 context: fork 派一个子代理去执行。这种模式的适用场景是一个独立完整的任务,不需要与主对话交互,执行完把结果送回来就行。
yaml
---
name: codebase-research
description: Deep research into codebase topics
context: fork # 关键点!
agent: Explore
---Research $ARGUMENTS thoroughly...
模式二的配套项目位于:04-Skills/projects/07-skill-fork-demo/。项目结构如下:
text
07-skill-fork-demo/
├── .claude/
│ └── skills/
│ └── code-health-check/
│ └── SKILL.md # context: fork + agent: general-purpose
├── src/
│ ├── app.js # 含硬编码密钥
│ ├── routes/
│ │ ├── products.js # 含 SQL 注入、缺少 try/catch
│ │ └── categories.js # 含未使用函数、重复逻辑
│ └── utils/
│ └── db.js # 含 eval() 使用
└── README.md在这个项目中,你想做一次代码质量扫描,但不想让大量中间文件内容污染主对话。这正是 context: fork 的典型场景——Skill 自己派一个子代理去做,做完把报告送回来。
这个项目和上一个项目(模式一)的区别是模式一(Project 05)需要 SubAgent .md 定义文件 + skills: 字段。而模式二(本项目Project 04)只需要 SKILL.md 一个文件,context: fork + agent: 自动搞定其它。
这个Skill 的设计如下。
yaml
---
name: code-health-check
description: Perform a comprehensive code health check on a directory.
context: fork # ← 关键:在隔离子代理中执行
agent: general-purpose # ← 子代理类型
allowed-tools: [Read, Grep, Glob] # ← 只读,不修改代码
---markdown
# Code Health Check
Analyze the codebase at `$ARGUMENTS` and produce a structured health report.
Checks to Perform
1. File Organization - 文件大小、目录结构
2. Error Handling - try/catch、错误传播
3. Security Basics - 硬编码密钥、eval()、SQL 注入
4. Code Quality - 重复代码、未使用变量
Output Format
Return a structured report:
- Overall health score (A/B/C/D/F)
- Issues found (categorized by severity: CRITICAL/WARNING/INFO)
- Top 3 recommendations
项目 07 的 src/ 中故意埋了多个安全和质量问题。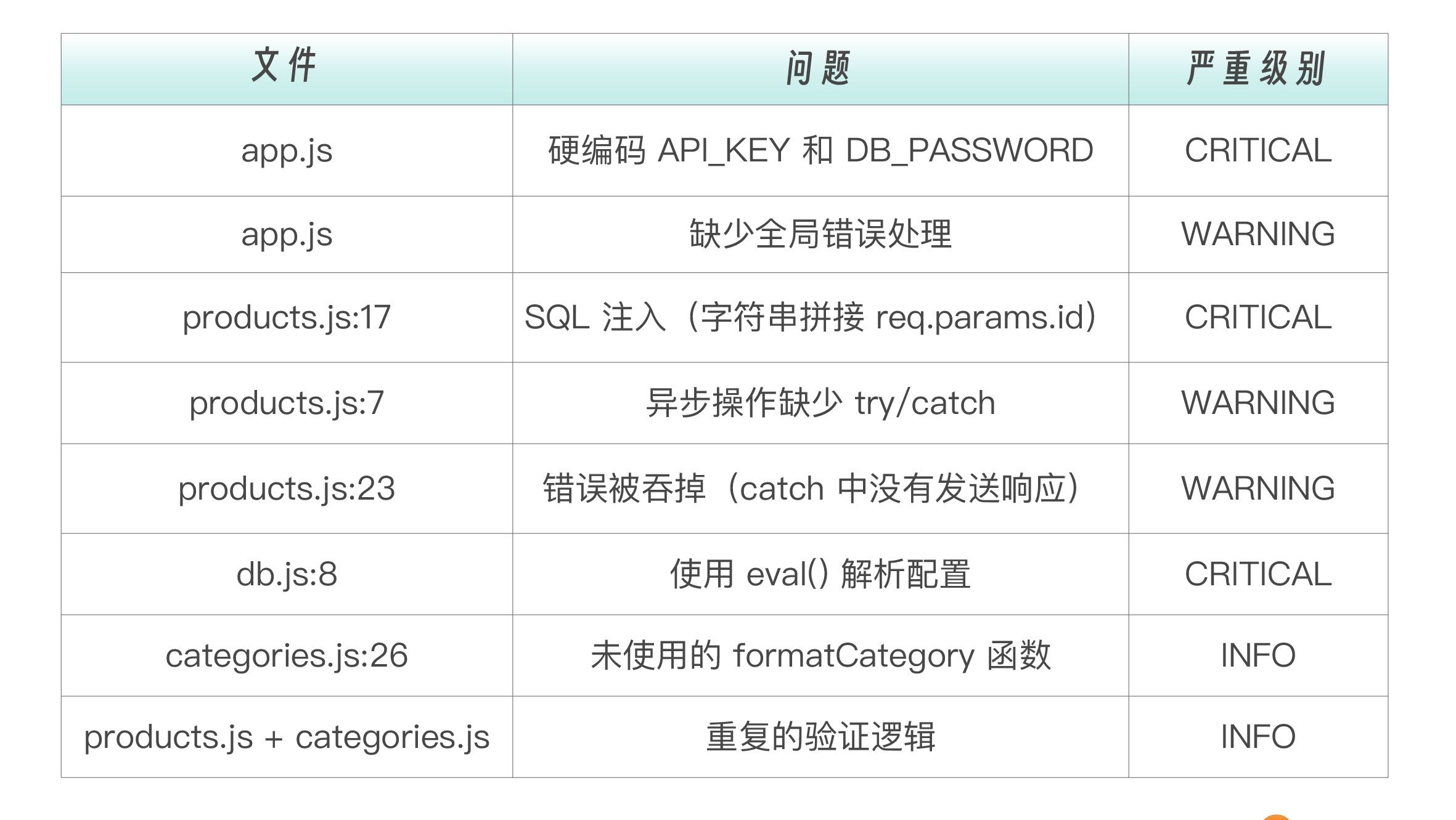
这些“已知答案“让你可以验证子代理的检查质量。
进入项目目录后,在 Claude Code 中执行:
/code-health-check src/
此时Claude Code的执行流程如下:
/code-health-check src/
text
│
├─ SKILL.md 被激活(context: fork)
├─ 自动创建 general-purpose 子代理
├─ 子代理在隔离上下文中:
│ ├─ Glob 扫描 src/ 下所有 .js 文件
│ ├─ Read 每个文件
│ ├─ Grep 搜索 eval(), hardcoded secrets 等模式
│ └─ 生成健康报告
└─ 返回报告到主对话(主对话上下文干净)此处的验证要点是:
是否发现了 3 个 CRITICAL 问题?(硬编码密钥、SQL 注入、eval)
是否发现了 WARNING 和 INFO 级别问题?
主对话上下文是否干净——你看不到子代理读文件的中间过程。
模式二的适用场景总结如下。
模式三:流水线中的 Skill 分工(方向 A 的多阶段串联)
下面我们再往前走一步。思考一下模式一的自然延伸——多个子代理各自预加载不同的 Skill,按阶段串联执行。每个阶段的输出作为下一阶段的输入。这种模式是和复杂的多阶段任务(我们之前子代理部分也介绍过类似的示例),但此处每个阶段需要通过Skill来配备不同的专业知识。
配套项目:04-Skills/projects/08-skill-pipeline/
项目整体结构如下。
text
08-skill-pipeline/
├── CLAUDE.md ← 流水线编排指令
├── .claude/
│ ├── agents/
│ │ ├── route-scanner.md ← 阶段 1: 路由扫描专家 (haiku)
│ │ ├── doc-writer.md ← 阶段 2: 文档编写专家 (sonnet)
│ │ └── quality-checker.md ← 阶段 3: 质量检查专家 (haiku)
│ ├── skills/
│ │ ├── route-scanning/
│ │ │ ├── SKILL.md ← 扫描工作流程
│ │ │ └── scripts/scan-routes.py ← 路由扫描脚本
│ │ ├── doc-writing/
│ │ │ ├── SKILL.md ← 文档生成工作流程
│ │ │ └── templates/endpoint-doc.md ← 文档模板
│ │ └── quality-checking/
│ │ ├── SKILL.md ← 质量检查工作流程
│ │ └── rules/doc-standards.md ← 质量标准规则
│ └── settings.local.json
├── src/routes/
│ ├── products.js ← 7 条路由(含链式路由)
│ └── categories.js ← 5 条路由
└── docs/ ← 生成的文档输出一个完整的 API 文档流程可以拆分为三个阶段,每个阶段需要不同的专业能力。
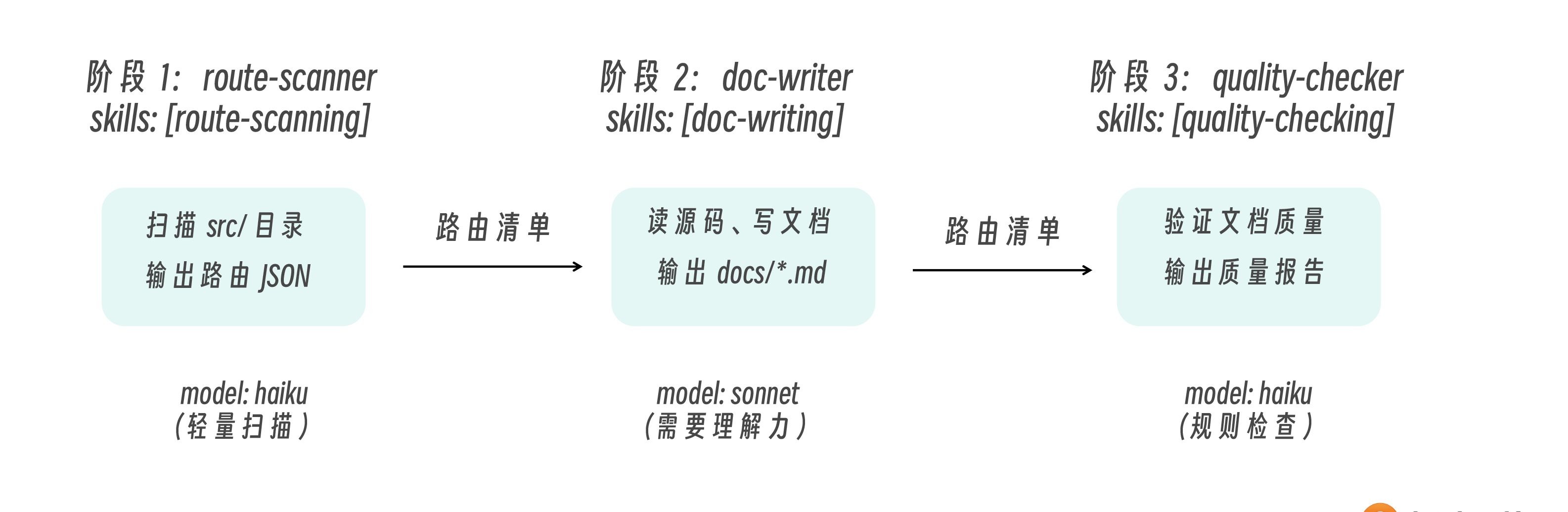
每一个阶段的输入输出流程如下。
阶段 1: 分析子代理
text
└─ skills: ["code-analyzing"]
└─ 输出:代码分析报告阶段 2: 重构子代理
text
└─ skills: ["refactoring-patterns"]
└─ 输入:阶段 1 的报告
└─ 输出:重构方案阶段 3: 测试子代理
text
└─ skills: ["testing-conventions"]
└─ 输入:阶段 2 的代码变更
└─ 输出:测试结果阶段 1:Route Scanner。对应 Skill route-scanning/SKILL.md:包含扫描脚本 scan-routes.py,输出 JSON 格式的路由清单。
.claude/agents/route-scanner.md
yaml
---
name: route-scanner
model: haiku # 轻量任务用 haiku
tools: [Read, Grep, Glob, Bash]
skills:
- route-scanning # 预加载扫描知识
---You are a route scanning specialist. You are Stage 1 of a documentation pipeline.
阶段 2:Doc Writer。对应 Skill doc-writing/SKILL.md:包含文档模板 endpoint-doc.md,按模板生成标准化文档。
.claude/agents/doc-writer.md
yaml
---
name: doc-writer
model: sonnet # 需要理解代码逻辑,用 sonnet
tools: [Read, Write, Glob]
skills:
- doc-writing # 预加载文档编写知识
---You are a documentation writing specialist. You are Stage 2 of a documentation pipeline.
阶段 3:Quality Checker。对应 Skill quality-checking/SKILL.md:包含质量标准规则 doc-standards.md,逐项检查文档质量。
.claude/agents/quality-checker.md
yaml
---
name: quality-checker
model: haiku # 规则检查用 haiku 足够
tools: [Read, Grep, Glob] # 只读,不修改文档
skills:
- quality-checking # 预加载质量检查知识
---You are a documentation quality specialist. You are Stage 3 of a documentation pipeline.
流水线的编排逻辑写在 CLAUDE.md 中:
markdown
# API Documentation Pipeline
When the user asks to run the documentation pipeline:
Stage 1: Route Scanning
Use the `route-scanner` agent to scan the source directory.
Collect the route manifest (JSON) from its output.
Stage 2: Documentation Generation
Use the `doc-writer` agent to generate documentation.
Pass the route manifest from Stage 1 as input context.
Stage 3: Quality Validation
Use the `quality-checker` agent to validate the generated docs.
Report the quality verdict to the user.
编排的关键在于每个阶段的输出是下一阶段的输入。Claude 主对话扮演“项目经理”角色,依次调用三个专家。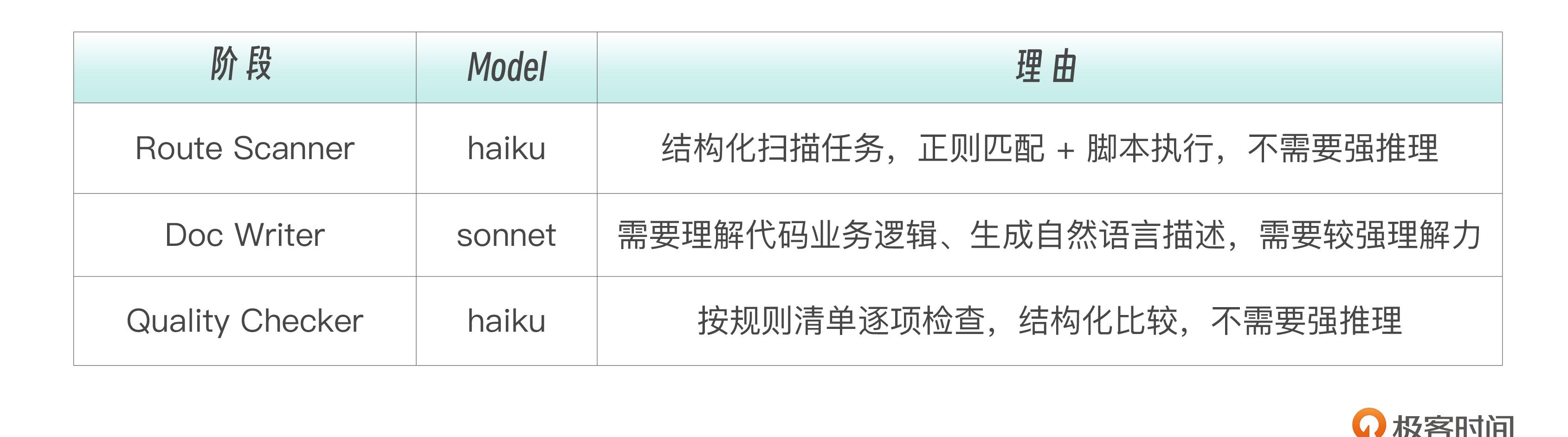
下面进行运行与验证。
先验证扫描脚本
python3 .claude/skills/route-scanning/scripts/scan-routes.py src/
预期:发现 12 条路由(products 7 条 + categories 5 条)
运行完整流水线
对 src/ 目录运行文档流水线
或者分阶段手动运行
用 route-scanner 扫描 src/ 目录的路由 用 doc-writer 根据上面的路由清单生成文档 用 quality-checker 验证 docs/ 目录下生成的文档
验证时需要注意下面几件事:
阶段 1 是否发现了全部 12 条路由?(包括链式路由 /:id/reviews)
阶段 2 是否生成了 docs/products-api.md 和 docs/categories-api.md?
阶段 3 的质量报告是 PASS 还是 NEEDS_REVISION?
对于流水线模式的设计,需要注意下面几个要点。
要点一:定义清晰的阶段间接口
每个阶段的 SKILL.md 都明确写了输出格式。
阶段 1 输出 JSON 路由清单
阶段 2 输出文件列表 + 路由覆盖数
阶段 3 输出 PASS/NEEDS_REVISION 报告
这些就是阶段间的“接口合约”。
要点二:每个 Skill 只关注一件事
route-scanning 只扫描路由,不生成文档。
doc-writing 只生成文档,不检查质量。
quality-checking 只检查质量,不修改文档。
单一职责让每个 Skill 更简洁、更可测试、更可复用。
要点三:编排逻辑集中管理
流水线的顺序、数据传递逻辑都放在 CLAUDE.md 中。如果要调整流程(比如跳过阶段 3),只需修改 CLAUDE.md,不需要动 Skill 或 SubAgent。
三种模式完整对照
为了帮你更好地理解和区分,我将这三种模式总结成了一张表。
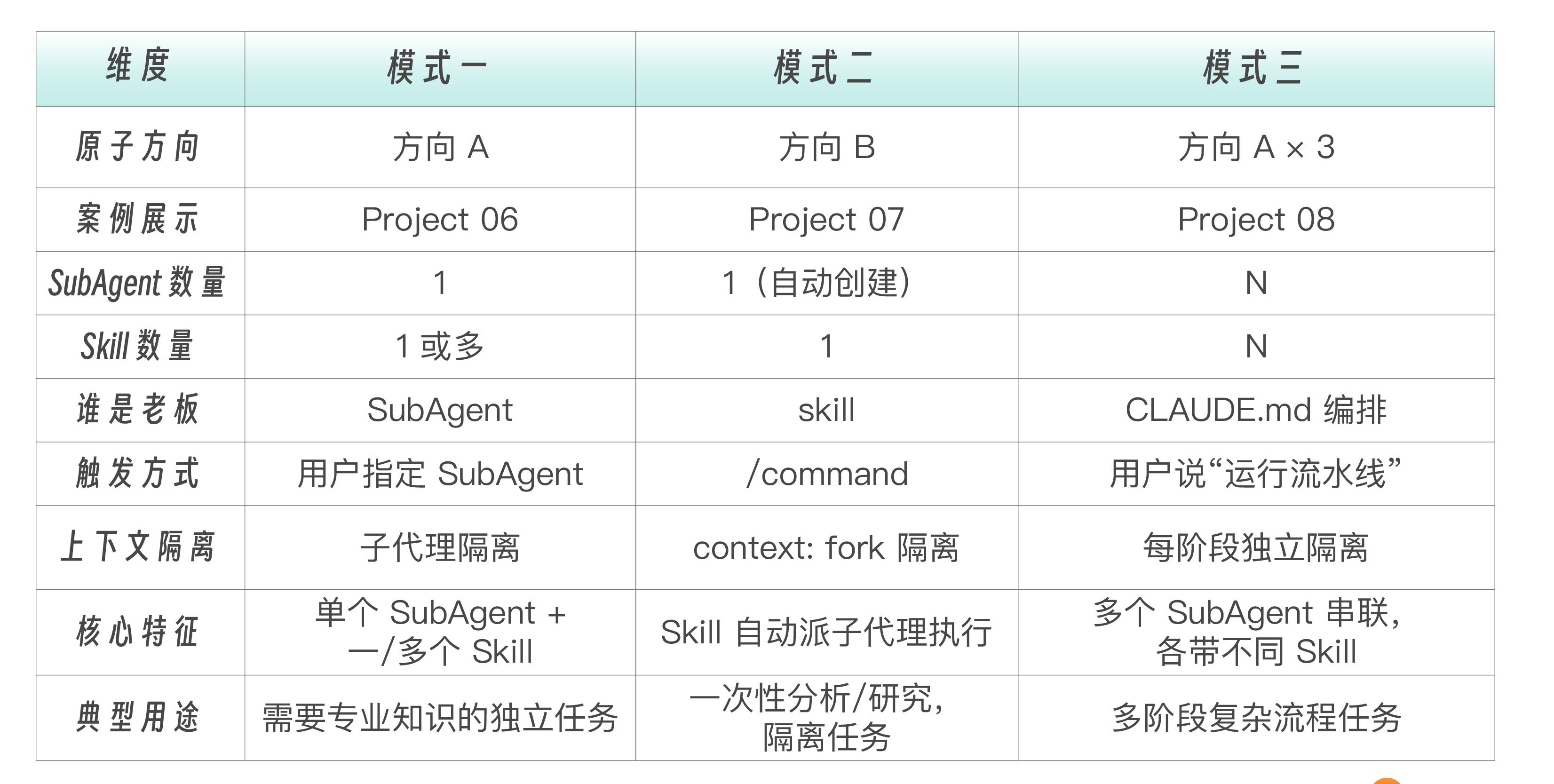
实际项目中,你觉得哪种模式最常用?——我感觉当然是第一种。
本讲小结
好,这一讲就到这里。本讲结构清晰,学习线路明确,比起重复要点,我更想分享一系列选型指南。
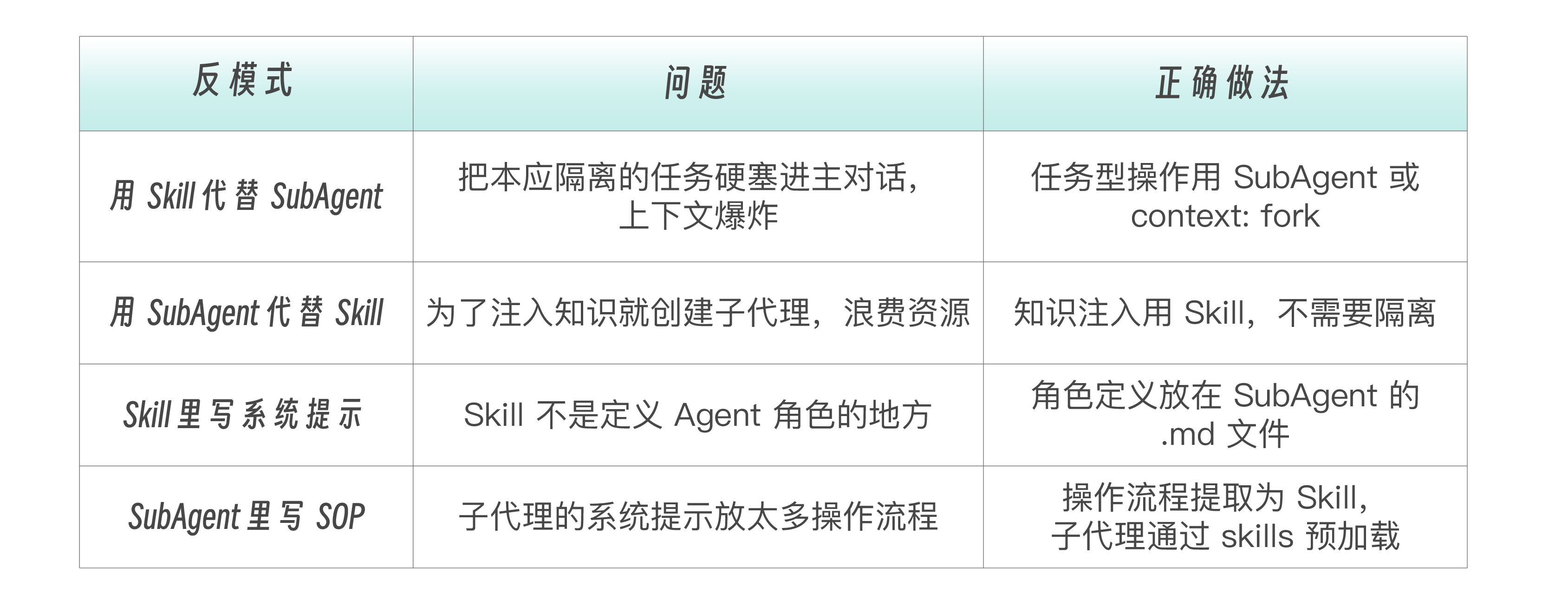
首先是各种场景下的选型矩阵和反模式警告。
说白了,还是用第一性原理区分什么时候用啥。这基于我们对于他们不同的职能的内化理解。
这种职责划分原则,贯穿几个项目的设计:
text
┌──────────────────────────────────────────────────────────────┐
│ 职责划分 │
│ │
│ SubAgent(.md 文件)负责: │
│ ──────────────────── │
│ • WHO: "You are an API documentation specialist" │
│ • WHAT: "Generate API documentation for Express routes" │
│ • WHERE: "Write to docs/api/" │
│ • OUTPUT: "Return summary with route count and warnings" │
│ │
│ Skill(SKILL.md + 附属文件)负责: │
│ ────────────────────────── │
│ • HOW: "Step 1: Run detect-routes.py → Step 2: Analyze" │
│ • WITH WHAT: scripts/detect-routes.py, templates/api-doc.md │
│ • BY WHAT STANDARD: "Check auth middleware, mark with 🔒" │
│ • QUALITY: "All routes documented, schemas match code" │
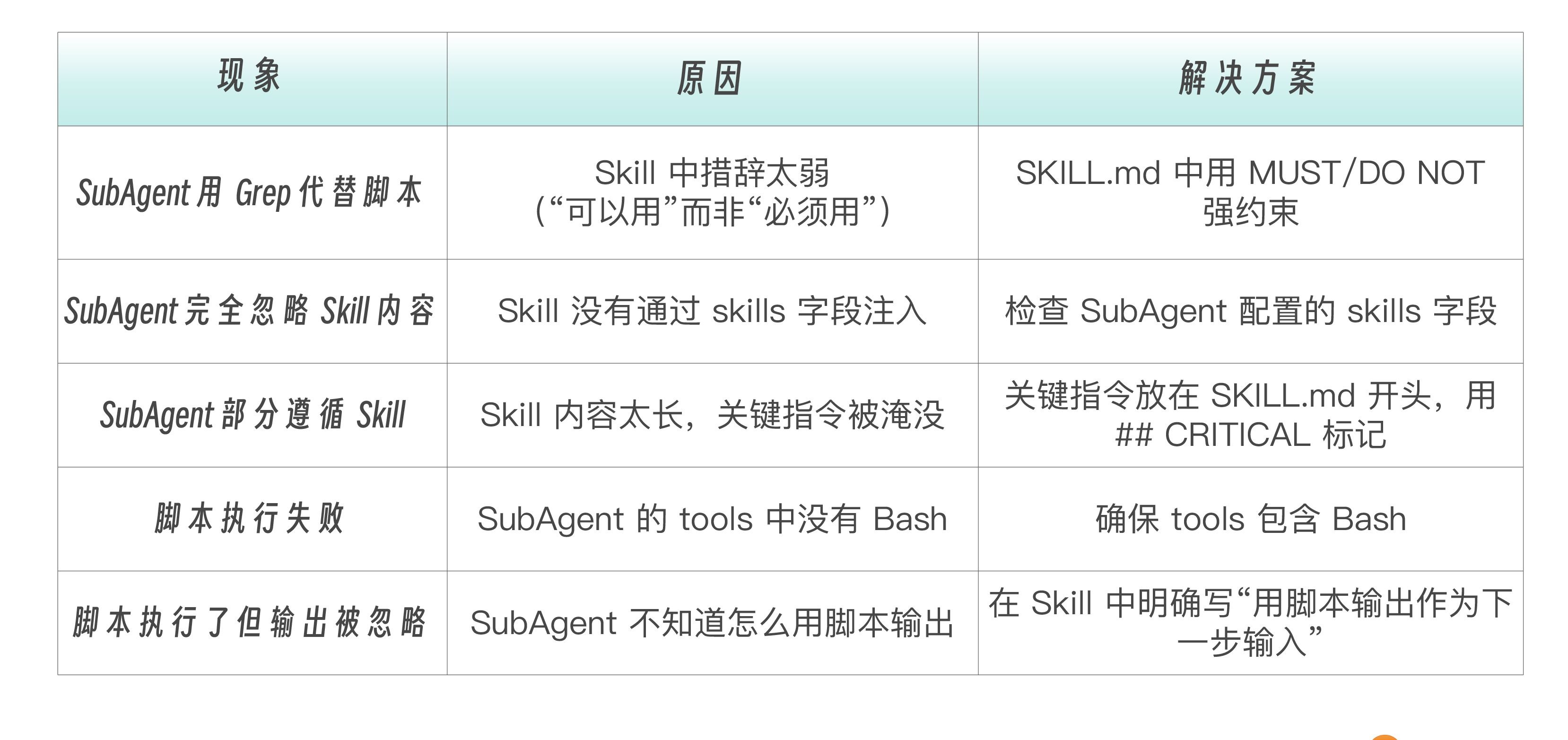
└──────────────────────────────────────────────────────────────┘这里我也给出组合过程中的排错速查表,供你参考。
最后的最后,就记住一句话。SubAgent 定义“是谁、做什么”,Skill 定义“怎么做、用什么做”。两者各有所长,组合才完整。
思考题
如果你的 Skill 需要调用外部 API(如翻译服务),你会如何设计?
模板和 CLAUDE.md 中的 prompt 有什么区别?什么时候用模板,什么时候用 prompt?
同一个 Skill 被不同角色的 SubAgent 预加载,执行效果会有什么不同?试着设想一个具体场景。
在项目 08 的流水线中,如果阶段 3 报告 NEEDS_REVISION,你会如何设计“自动修复”流程?需要修改哪些文件?
设计一个你自己项目中的流水线:画出阶段划分、每阶段的 SubAgent 角色和 Skill 职责、阶段间的数据接口。
下一讲预告
本讲我们掌握了 Skills 的高级模式和 SubAgent 配合实战。
下一讲我们将站在更高的视角——Skills 在 Claude Code 五层架构中的定位,从五层架构全景定位到四种设计模式,看清 Skills 在整个技术栈中的角色,最终画出 Skills 在整个技术栈中的全景定位图。